Authors: T.Y.S.S. Santosh, Irtiza Chowdhury, Shanshan Xu, Matthias Grabmair
Published on: September 27, 2024
Impact Score: 7.6
Arxiv code: Arxiv:2409.18645
Summary
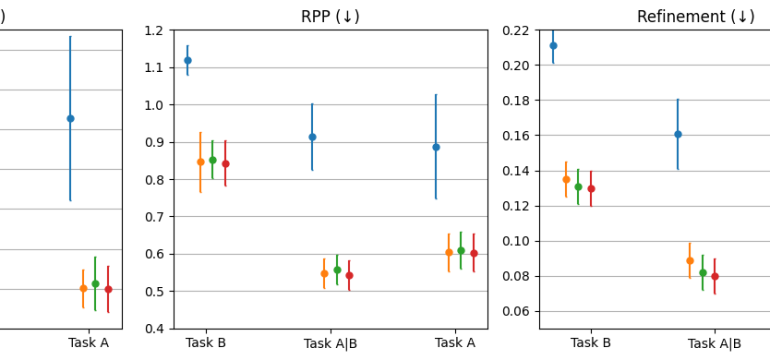
- What is new: This is the first systematic exploration of selective prediction in the field of legal NLP, focusing on how different design choices impact the reliability of models used for Case Outcome Classification.
- Why this is important: High-stakes decisions in legal contexts need reliable confidence estimates from NLP models to prevent significant errors.
- What the research proposes: Investigate how pre-training corpus, confidence estimators, and fine-tuning losses affect model reliability, and implement techniques like Monte Carlo dropout and confident error regularization to improve prediction confidence.
- Results: Diverse, domain-specific pre-training improves calibration; larger models tend to be overconfident; Monte Carlo dropout methods provide reliable confidence estimates and confident error regularization reduces overconfidence.
Technical Details
Technological frameworks used: Selective prediction framework
Models used: Monte Carlo dropout, confident error regularization
Data used: European Court of Human Rights (ECtHR) cases
Potential Impact
Legal tech firms and industries that rely on legal decision-support systems could benefit from improved model reliability and confidence estimation.
Want to implement this idea in a business?
We have generated a startup concept here: LegalPredictAI.


Leave a Reply