Authors: Shaina Raza, Ananya Raval, Veronica Chatrath
Published on: May 18, 2024
Impact Score: 7.6
Arxiv code: Arxiv:2405.11290
Summary
- What is new: MBIAS introduces a novel dataset and instruction fine-tuning approach specifically aimed at reducing bias and toxicity in LLM outputs without losing contextual accuracy.
- Why this is important: Existing LLMs, while producing safe outputs, often lose contextual meaning during the process of reducing bias and toxicity.
- What the research proposes: MBIAS, a LLM framework that uses instruction fine-tuning on a custom dataset tailored for safety interventions to preserve contextual accuracy while minimizing bias and toxicity.
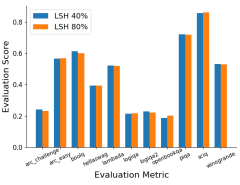
- Results: MBIAS achieved a over 30% reduction in bias and toxicity while retaining important information, with reductions exceeding 90% in various demographics on out-of-distribution tests.
Technical Details
Technological frameworks used: MBIAS
Models used: Large Language Models (LLMs)
Data used: Custom dataset for safety interventions
Potential Impact
Technology firms developing AI language models, social media platforms, and content moderation services could benefit significantly from the deployment of MBIAS.
Want to implement this idea in a business?
We have generated a startup concept here: EthicoAI.


Leave a Reply