Authors: Seungwook Han, Idan Shenfeld, Akash Srivastava, Yoon Kim, Pulkit Agrawal
Published on: May 10, 2024
Impact Score: 7.6
Arxiv code: Arxiv:2405.06639
Summary
- What is new: Introducing Value Augmented Sampling (VAS) for LLM adaptation, capable of optimizing rewards without accessing the LLM’s internal weights and outperforming existing RL methods.
- Why this is important: The challenge in aligning Large Language Models (LLMs) with human preferences while learning new skills and unlearning harmful behaviors in a cost-effective manner.
- What the research proposes: VAS, a new framework for reward optimization that works by maximizing reward functions using data sampled from an unchanged, initial LLM, avoiding the high costs and optimization challenges of other methods.
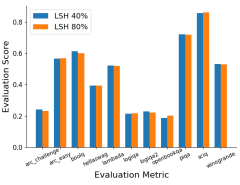
- Results: VAS outperformed established RL baselines on standard benchmarks, achieved comparable results to Best-of-128 with lower inference costs, and can adapt LLMs available only as APIs.
Technical Details
Technological frameworks used: Value Augmented Sampling (VAS)
Models used: Large Language Models (LLMs), PPO, DPO
Data used: Data sampled from the initial, unchanged LLM
Potential Impact
Markets of text-based AI services and companies relying on LLMs for content generation, customer service, or decision support systems could benefit or face disruption due to the enhanced adaptability and efficiency of LLM adaptation.
Want to implement this idea in a business?
We have generated a startup concept here: AdaptAI.

Leave a Reply