Authors: Yuta Saito, Himan Abdollahpouri, Jesse Anderton, Ben Carterette, Mounia Lalmas
Published on: April 24, 2024
Impact Score: 7.4
Arxiv code: Arxiv:2404.15691
Summary
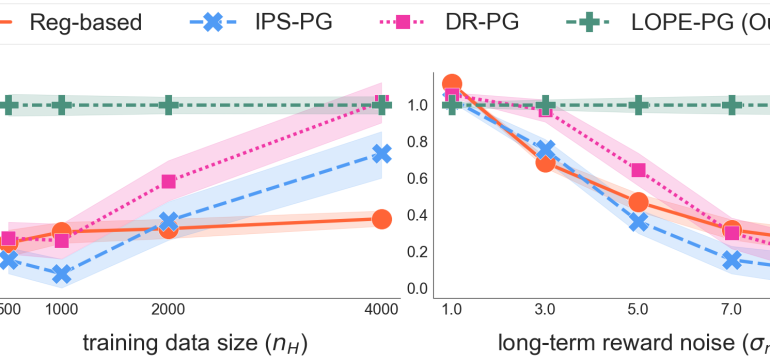
- What is new: A new framework called Long-term Off-Policy Evaluation (LOPE) that estimates long-term outcomes of an algorithm using historical and short-term experiment data.
- Why this is important: Difficulty in estimating the long-term outcomes of algorithms due to delayed effects, which makes algorithm selection slow.
- What the research proposes: LOPE, which uses reward function decomposition to leverage short-term rewards for estimating long-term outcomes under a relaxed set of assumptions.
- Results: LOPE outperforms existing methods, especially when existing assumptions do not hold and in the presence of noisy long-term rewards. It proved more accurate in real-world tests on a music streaming platform.
Technical Details
Technological frameworks used: Long-term Off-Policy Evaluation (LOPE)
Models used: nan
Data used: Historical and short-term experimental data, real-world A/B test data from a music streaming platform
Potential Impact
Online platforms and companies relying on user engagement metrics could benefit, including music streaming services, e-commerce, and social media platforms.
Want to implement this idea in a business?
We have generated a startup concept here: FutureSight Analytics.


Leave a Reply