Authors: Mathav Raj J, Kushala VM, Harikrishna Warrier, Yogesh Gupta
Published on: March 23, 2024
Impact Score: 7.2
Arxiv code: Arxiv:2404.10779
Summary
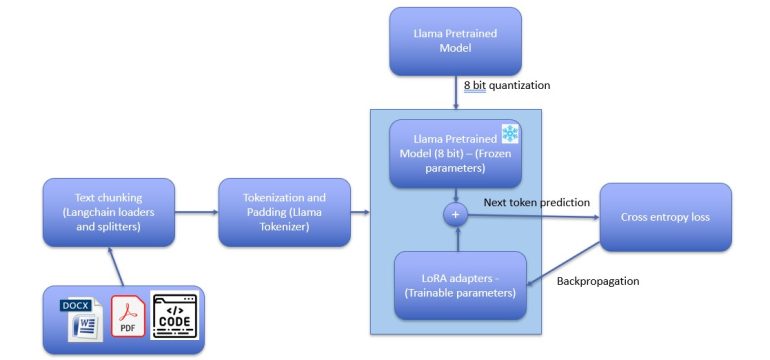
- What is new: The paper presents a novel approach to fine-tuning Large Language Models (LLMs) using proprietary documents and codes within enterprises, specifically focusing on open-source LLMs like LLaMA and offering detailed guidance on data preparation.
- Why this is important: Enterprises need to tailor LLMs with their proprietary domain knowledge efficiently, facing challenges in optimizing resource use, cost, and time without relying on limited Retrieval Augmented Generation (RAG) methods.
- What the research proposes: Fine-tuning LLaMA with enterprise-specific documents and codes, introducing pre-processing recipes for data in various formats, and providing practical guidelines for efficient model training.
- Results: The fine-tuned models showed improved quality in domain-specific responses, demonstrating the efficacy of the proposed data preparation methods and tuning guidelines.
Technical Details
Technological frameworks used: LLaMA for fine-tuning
Models used: Large Language Models (LLMs)
Data used: Proprietary enterprise documents and code repositories
Potential Impact
This research could impact a wide array of industries reliant on LLMs for handling domain-specific tasks, including tech companies developing AI solutions, legal firms, medical research institutions, and any enterprise aiming to leverage LLMs for proprietary knowledge processing.
Want to implement this idea in a business?
We have generated a startup concept here: DomainTune AI.


Leave a Reply