Authors: Chenxin An, Fei Huang, Jun Zhang, Shansan Gong, Xipeng Qiu, Chang Zhou, Lingpeng Kong
Published on: February 27, 2024
Impact Score: 8.0
Arxiv code: Arxiv:2402.17463
Summary
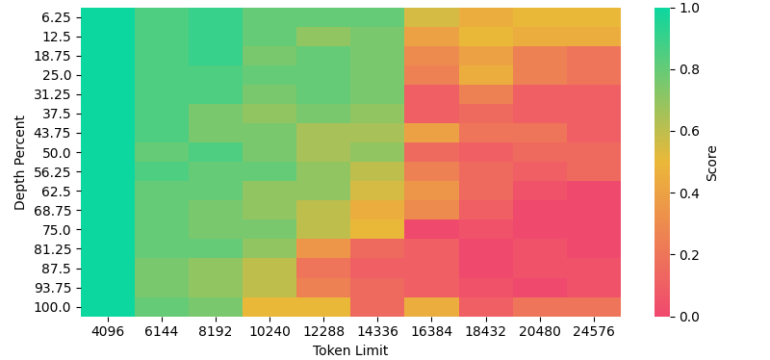
- What is new: Introduction of the Dual Chunk Attention (DCA) mechanism for processing long sequences of text without the need for continual training.
- Why this is important: Large Language Models struggle with processing text beyond their pretraining length and finetuning them for longer sequences is resource-intensive.
- What the research proposes: Dual Chunk Attention (DCA) enables Llama2 70B to support over 100k tokens context windows efficiently by breaking down attention computations into manageable chunks.
- Results: DCA matches or exceeds the performance of finetuned models on long-context tasks and achieves 94% of the capabilities of gpt-3.5-16k, offering an effective open-source alternative.
Technical Details
Technological frameworks used: Dual Chunk Attention (DCA), integrated with Flash Attention
Models used: Llama2 70B
Data used: nan
Potential Impact
This advancement could impact the AI research and development landscape, particularly benefiting companies focused on natural language processing, content generation, and analysis tools requiring long-context understanding.
Want to implement this idea in a business?
We have generated a startup concept here: DCAIdee.


Leave a Reply