Authors: Rares Dolga, Marius Cobzarenco, David Barber
Published on: February 27, 2024
Impact Score: 8.0
Arxiv code: Arxiv:2402.17512
Summary
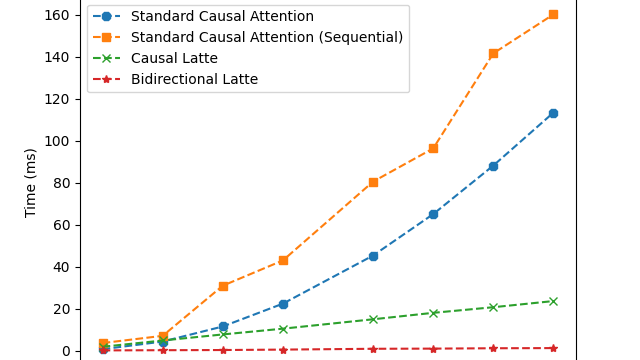
- What is new: Introduces a method to make attention mechanisms in transformers scale linearly with the length, using latent vectors.
- Why this is important: Standard transformer attention mechanisms have a quadratic scaling problem with the sequence length.
- What the research proposes: A new ‘Latte Transformer’ model that utilizes latent vectors for attention, allowing linear scalability.
- Results: Empirical performance is comparable to standard attention but supports much larger context windows efficiently.
Technical Details
Technological frameworks used: Transformer models with attention mechanisms
Models used: Latte Transformer
Data used: language generation tasks
Potential Impact
Technology companies invested in natural language processing and AI-driven analytics could benefit significantly.
Want to implement this idea in a business?
We have generated a startup concept here: StreamLineAI.


Leave a Reply