Authors: Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, Mao Yang
Published on: February 21, 2024
Impact Score: 8.0
Arxiv code: Arxiv:2402.13753
Summary
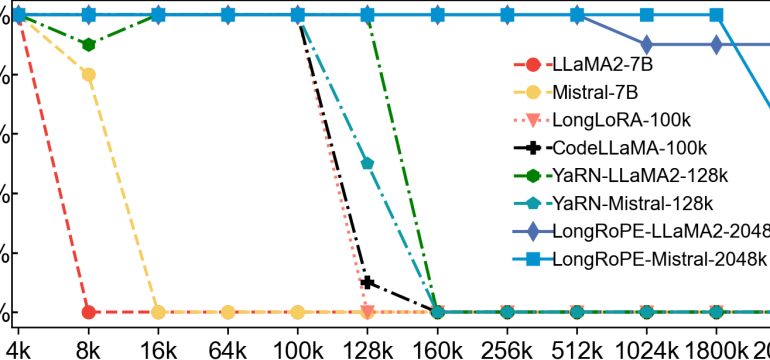
- What is new: LongRoPE extends the context window of pre-trained LLMs to 2048k tokens, a significant leap from the current limit of around 128k tokens.
- Why this is important: Extending the context window of large language models is challenging due to high fine-tuning costs, scarcity of long texts, and issues introduced by new token positions.
- What the research proposes: LongRoPE achieves the extension through a novel strategy involving non-uniform positional interpolation, a progressive extension strategy, and readjustment for short context performance.
- Results: Models extended with LongRoPE can handle up to 2048k tokens with minimal fine-tuning, maintaining performance at short context windows across various tasks on LLaMA2 and Mistral.
Technical Details
Technological frameworks used: nan
Models used: LLaMA2, Mistral
Data used: nan
Potential Impact
This research could impact markets that rely on large language models, such as content creation, automated programming assistance, and long-form text analysis.
Want to implement this idea in a business?
We have generated a startup concept here: ExpansioAI.


Leave a Reply