Authors: Neslihan Suzen, Evgeny M. Mirkes, Damian Roland, Jeremy Levesley, Alexander N. Gorban, Tim J. Coats
Published on: February 09, 2024
Impact Score: 8.35
Arxiv code: Arxiv:2402.06563
Summary
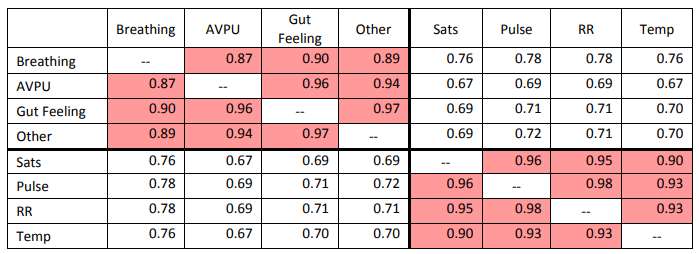
- What is new: The research breaks new ground by showing that missing data in EPRs are likely non-random and explaining the link to health care professionals’ practice patterns. It also introduces an effective imputation method using k-Nearest Neighbour for paediatric emergency and trauma case data.
- Why this is important: Missing information in Electronic Patient Records (EPRs) can introduce bias in clinical data analysis, affecting the validity of clinical decisions.
- What the research proposes: The study proposes using statistical approaches and machine learning techniques, specifically Singular Value Decomposition (SVD) and k-Nearest Neighbour (kNN) for imputing missing data in EPRs.
- Results: Among the tested methods, the 1NN imputer yielded the best results, suggesting that imputing attributes from the most similar patients is an effective strategy.
Technical Details
Technological frameworks used: nan
Models used: SVD, kNN
Data used: Paediatric emergency data, TARN database
Potential Impact
Healthcare providers and institutions, Electronic Health Record (EHR) system vendors, companies specializing in health data analytics.
Want to implement this idea in a business?
We have generated a startup concept here: HealFill.


Leave a Reply