Authors: Di Cao, Xianchen Wang, Junfeng Zhou, Jiakai Zhang, Yanjing Lei, Wenpeng Chen
Published on: February 08, 2024
Impact Score: 8.15
Arxiv code: Arxiv:2402.06073
Summary
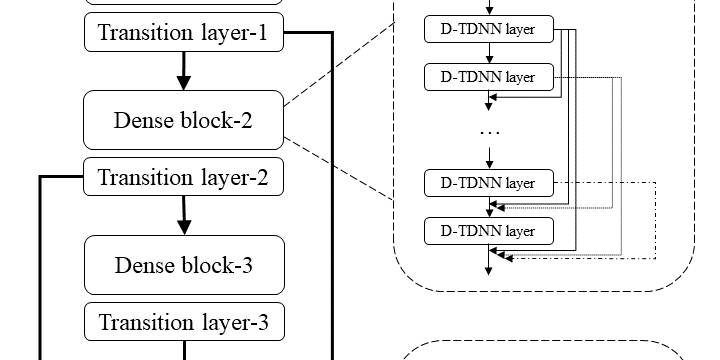
- What is new: LightCAM introduces a combination of depthwise separable convolution and multi-scale feature aggregation to the Dense TDNN framework, enhancing efficiency.
- Why this is important: Traditional TDNNs are powerful for tasks like speaker verification but are computationally expensive and slow, hindering their industrial application.
- What the research proposes: The proposed LightCAM model incorporates DSM and MFA to reduce computational complexity and speed up inference while maintaining high performance.
- Results: LightCAM achieved superior performance in speaker verification on the VoxCeleb dataset with lower computational costs and faster processing times.
Technical Details
Technological frameworks used: Densely Connected Time Delay Neural Network (D-TDNN) with Context Aware Masking (CAM)
Models used: Depthwise Separable Module (DSM), Multi-Scale Feature Aggregation (MFA)
Data used: VoxCeleb dataset
Potential Impact
Voice recognition software providers, security and authentication service companies, and industries requiring efficient voice-based technologies
Want to implement this idea in a business?
We have generated a startup concept here: VoiceLock.

Leave a Reply