Authors: Tu Anh Nguyen, Benjamin Muller, Bokai Yu, Marta R. Costa-jussa, Maha Elbayad, Sravya Popuri, Paul-Ambroise Duquenne, Robin Algayres, Ruslan Mavlyutov, Itai Gat, Gabriel Synnaeve, Juan Pino, Benoit Sagot, Emmanuel Dupoux
Published on: February 08, 2024
Impact Score: 8.22
Arxiv code: Arxiv:2402.05755
Summary
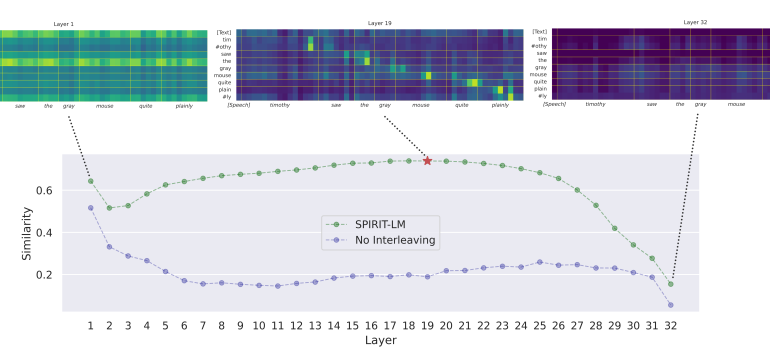
- What is new: SPIRIT-LM combines text and speech in one model, using a novel word-level interleaving method and introducing expressivity features.
- Why this is important: Prior models treated text and speech separately, lacking a unified approach to understanding both modalities together.
- What the research proposes: SPIRIT-LM extends a text-based model to handle speech by training on combined speech and text tokens, including expressivity aspects in its EXPRESSIVE version.
- Results: SPIRIT-LM effectively learns and performs tasks across both modalities and demonstrates superior semantic and expressive capabilities.
Technical Details
Technological frameworks used: Pretrained text language model extended for speech
Models used: BASE and EXPRESSIVE versions for semantic and expressivity features respectively
Data used: Automatically-curated speech-text parallel corpus
Potential Impact
Language technology providers, educational tech, content creation platforms, and customer service automation.
Want to implement this idea in a business?
We have generated a startup concept here: ExprEssence.

Leave a Reply