Authors: Peng Gao, Renrui Zhang, Chris Liu, Longtian Qiu, Siyuan Huang, Weifeng Lin, Shitian Zhao, Shijie Geng, Ziyi Lin, Peng Jin, Kaipeng Zhang, Wenqi Shao, Chao Xu, Conghui He, Junjun He, Hao Shao, Pan Lu, Hongsheng Li, Yu Qiao
Published on: February 08, 2024
Impact Score: 8.3
Arxiv code: Arxiv:2402.05935
Summary
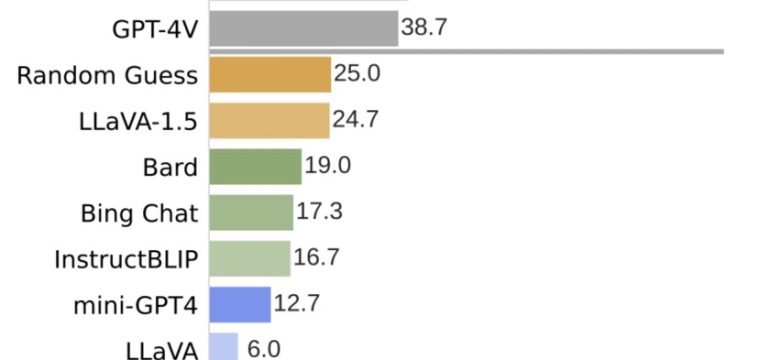
- What is new: Introduction of an enhanced Multimodality Large Language Model (MLLM) series, SPHINX-X, which streamlines the original SPHINX framework for higher efficiency and broader applicability.
- Why this is important: The need for more efficient and effective multimodal large language models that can handle diverse datasets spanning various domains.
- What the research proposes: Modification of SPHINX by eliminating unnecessary components and simplifying training processes, coupled with the creation of a comprehensive multi-domain and multimodal dataset.
- Results: A spectrum of MLLMs with varying sizes and capabilities that demonstrate a significant performance correlation with data and parameter scale.
Technical Details
Technological frameworks used: SPHINX modified framework
Models used: TinyLlama1.1B, InternLM2-7B, LLaMA2-13B, and Mixtral8x7B
Data used: Multi-domain and multimodal dataset, including OCR intensive and Set-of-Mark datasets
Potential Impact
This could affect companies in the tech industry that specialize in AI, machine learning services, content moderation, autonomous systems, and potentially broader sectors like marketing and security surveillance that rely on advanced language and image processing.
Want to implement this idea in a business?
We have generated a startup concept here: InfoFusion Genie.


Leave a Reply