Authors: Ziyi Yin, Muchao Ye, Tianrong Zhang, Tianyu Du, Jinguo Zhu, Han Liu, Jinghui Chen, Ting Wang, Fenglong Ma
Published on: October 07, 2023
Impact Score: 8.22
Arxiv code: Arxiv:2310.04655
Summary
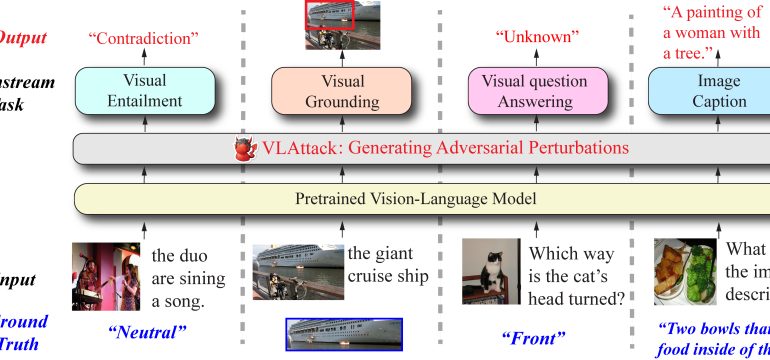
- What is new: Introduces VLATTACK that combines both image and text perturbations for attacking black-box models, utilizing a new block-wise similarity attack strategy for images and an iterative cross-search attack method for multimodal levels.
- Why this is important: The adversarial robustness of Vision-Language pre-trained models has not been thoroughly put to the test in realistic scenarios outside the white-box setting.
- What the research proposes: VLATTACK method that fuses image and text perturbations at both the single-modal and multimodal levels to generate adversarial samples capable of effectively attacking black-box models.
- Results: VLATTACK achieved the highest attack success rates across all tasks when compared to other state-of-the-art methods, highlighting a significant blind spot in the security of pre-trained VL models.
Technical Details
Technological frameworks used: Block-wise similarity attack (BSA) for images, existing text attack strategies, Iterative cross-search attack (ICSA) for multimodal levels.
Models used: Five widely-used Vision-Language pre-trained models
Data used: Datasets comprising images and texts for six different tasks
Potential Impact
This research could impact a variety of markets relying on Vision-Language models, including social media platforms, security firms, autonomous vehicle companies, and any business utilizing AI for image and text analysis.
Want to implement this idea in a business?
We have generated a startup concept here: SecureVisionAI.


Leave a Reply