Authors: Da Yu, Sivakanth Gopi, Janardhan Kulkarni, Zinan Lin, Saurabh Naik, Tomasz Lukasz Religa, Jian Yin, Huishuai Zhang
Published on: May 23, 2023
Impact Score: 8.45
Arxiv code: Arxiv:2305.13865
Summary
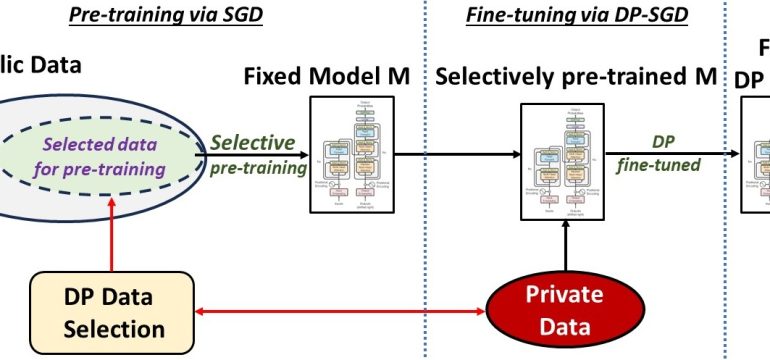
- What is new: A new framework for training small, fast, and private language models that outperforms existing models.
- Why this is important: How to train text prediction models that are small, efficient, and protect user privacy.
- What the research proposes: Pre-training on a public dataset guided by private data, followed by private fine-tuning.
- Results: State-of-the-art performance on benchmarks and real-world deployments, achieving significant inference cost savings.
Technical Details
Technological frameworks used: New framework for private and efficient language model training.
Models used: Domain-specific language models.
Data used: Public datasets guided by private datasets.
Potential Impact
Email clients, word processors, healthcare, finance sectors, and companies requiring efficient, privacy-preserving text prediction models.
Want to implement this idea in a business?
We have generated a startup concept here: PrivTune.

Leave a Reply