Authors: Praneeth Kacham, Vahab Mirrokni, Peilin Zhong
Published on: October 02, 2023
Impact Score: 8.22
Arxiv code: Arxiv:2310.01655
Summary
- What is new: Uses polynomial attention and sketching techniques for linear-time Transformer architecture, improving efficiency without losing quality.
- Why this is important: Self-attention mechanisms in large-scale Transformers have quadratic time and memory complexity, creating a computational bottleneck.
- What the research proposes: Introducing polynomial attention with polynomial sketching techniques to achieve linear-time complexity without needing to sparsify attention matrices.
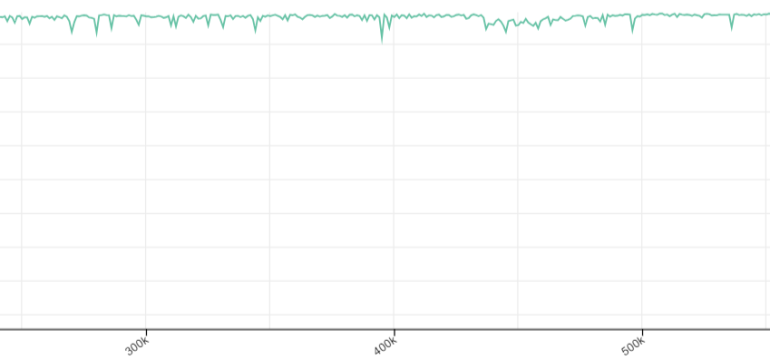
- Results: Achieved a 2.5-4x speedup in training language models on long contexts with no degradation in quality, compared to FlashAttention.
Technical Details
Technological frameworks used: PolySketchFormer, a linear-time Transformer architecture
Models used: GPT-2 style models
Data used: PG19, Wikipedia, C4 datasets on Google Cloud TPUs
Potential Impact
Cloud computing, AI research and development firms, companies invested in NLP technologies
Want to implement this idea in a business?
We have generated a startup concept here: Polyscale AI.


Leave a Reply