Authors: Shashank Sonkar, Kangqi Ni, Sapana Chaudhary, Richard G. Baraniuk
Published on: February 07, 2024
Impact Score: 8.3
Arxiv code: Arxiv:2402.05000
Summary
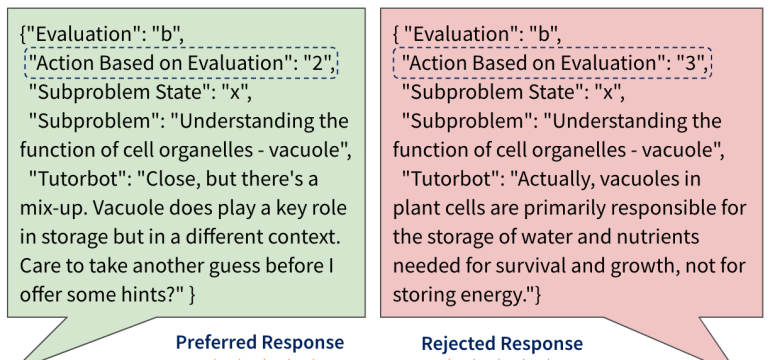
- What is new: Introduction of pedagogically aligned Large Language Models (LLMs) utilizing reinforcement learning through human feedback (RLHF) for educational purposes.
- Why this is important: Direct response LLMs lack the ability to properly scaffold learning experiences, limiting their effectiveness in educational settings.
- What the research proposes: A novel approach that employs RLHF methods to create pedagogically-aligned LLMs that guide learners through problem-solving processes.
- Results: RLHF algorithms outperform supervised finetuning significantly, with qualitative analysis supporting RLHF’s superiority in pedagogical alignment.
Technical Details
Technological frameworks used: RLHF
Models used: State-of-the-art RLHF algorithms
Data used: Reward dataset specifically designed for pedagogical alignment
Potential Impact
Educational technology firms, online tutoring services, and platforms offering AI-based learning solutions
Want to implement this idea in a business?
We have generated a startup concept here: EduScaffold.



Leave a Reply