Authors: Ningyuan Tang, Minghao Fu, Ke Zhu, Jianxin Wu
Published on: February 06, 2024
Impact Score: 8.22
Arxiv code: Arxiv:2402.04009
Summary
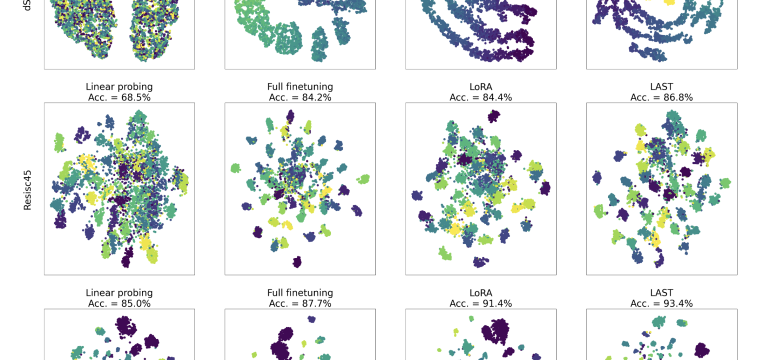
- What is new: Introduces Low-rank Attention Side-Tuning (LAST) that separates the trainable module from the pretrained model, reducing GPU memory usage and training time while maintaining high accuracy.
- Why this is important: Parameter-efficient fine-tuning (PEFT) methods are effective but suffer from high GPU memory consumption and slow training speeds.
- What the research proposes: LAST uses a side-network of low-rank self-attention modules that takes output from a frozen pretrained model, focusing on learning task-specific knowledge efficiently.
- Results: LAST outperforms state-of-the-art methods in visual adaptation tasks, using about 30% of the GPU memory footprint and 60% of the training time, while achieving significantly higher accuracy.
Technical Details
Technological frameworks used: nan
Models used: Low-rank self-attention modules
Data used: nan
Potential Impact
Technology companies in AI and machine learning spaces, especially those providing or utilizing visual adaptation and fine-tuning services, could benefit from LAST’s efficiency and accuracy improvements.
Want to implement this idea in a business?
We have generated a startup concept here: EffiModel.

Leave a Reply