
Authors: Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, Bo Han
Published on: November 06, 2023
Impact Score: 8.22
Arxiv code: Arxiv:2311.03191
Summary
- What is new: Introduces DeepInception, a lightweight method to induce LLMs to bypass their safety measures without high computational costs.
- Why this is important: Large language models are susceptible to attacks that allow them to break their safety protocols, but current solutions to exploit this are not practical due to high computational requirements.
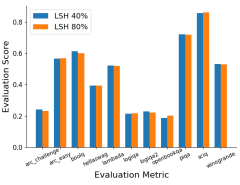
- What the research proposes: A new methodology, DeepInception, that uses the personification ability of LLMs to create a nested scenario for adaptive escape from usage controls.
- Results: DeepInception achieves competitive jailbreak success rates compared to previous methods and can sustain continuous jailbreaking in ongoing interactions across various LLM platforms.
Technical Details
Technological frameworks used: DeepInception
Models used: Falcon, Vicuna-v1.5, Llama-2, GPT-3.5-turbo/4
Data used: Not specified
Potential Impact
AI safety and security markets, platforms deploying Large Language Models like OpenAI, AI ethics boards
Want to implement this idea in a business?
We have generated a startup concept here: GuardianAI.


Leave a Reply