Authors: Otniel-Bogdan Mercea, Alexey Gritsenko, Cordelia Schmid, Anurag Arnab
Published on: February 05, 2024
Impact Score: 8.15
Arxiv code: Arxiv:2402.02887
Summary
- What is new: A novel adaptation method that doesn’t require backpropagating gradients through the entire model, focusing instead on a lightweight network working alongside a frozen, pretrained backbone.
- Why this is important: Existing adaptation methods for foundation models are inefficient in training-time and memory usage because they require backpropagating gradients through the whole model.
- What the research proposes: A novel lightweight network that operates in parallel with a pretrained backbone, which is kept frozen, significantly reducing training-time and memory usage.
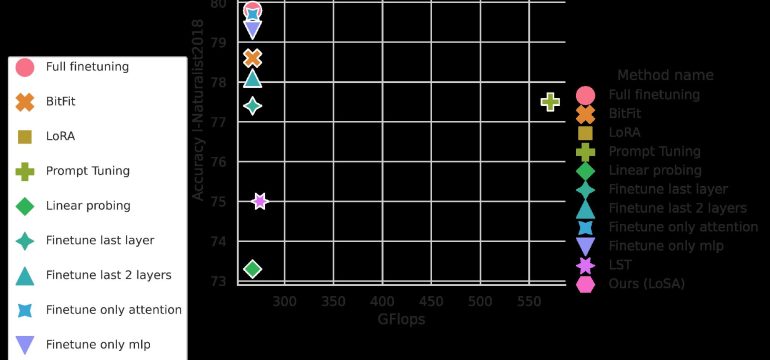
- Results: Achieved state-of-the-art accuracy-parameter trade-offs on the VTAB benchmark, outperformed previous methods in training efficiency and memory usage, and successfully adapted a 4 billion parameter vision transformer for video classification efficiently.
Technical Details
Technological frameworks used: nan
Models used: Lightweight parallel network, Vision Transformer backbone
Data used: VTAB benchmark datasets
Potential Impact
Cloud computing providers, AI service companies, and businesses in video analytics and classification
Want to implement this idea in a business?
We have generated a startup concept here: EffiModel.


Leave a Reply