Authors: Atharva Kulkarni, Bo-Hsiang Tseng, Joel Ruben Antony Moniz, Dhivya Piraviperumal, Hong Yu, Shruti Bhargava
Published on: February 03, 2024
Impact Score: 8.07
Arxiv code: Arxiv:2402.02285
Summary
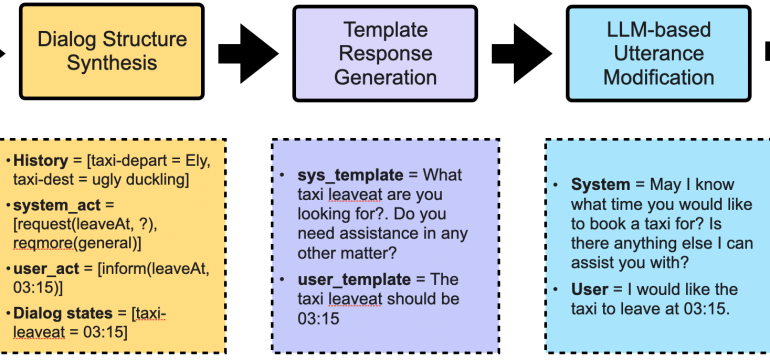
- What is new: The introduction of a new data generation framework, \method, which synthesizes natural dialogues for Dialog State Tracking (DST) without needing extensive labeled training data.
- Why this is important: The difficulty in obtaining labeled training data for DST across a wide range of domains and applications, and the performance gap between zero-shot and few-shot learning methods.
- What the research proposes: \method, a framework that generates synthetic dialogue data tailored for DST by using only the dialogue schema and a few dialogue templates, enabling effective few-shot learning.
- Results: Using synthetic data from \method for few-shot learning resulted in a 4-5% improvement in Joint Goal Accuracy over the zero-shot baseline on MultiWOZ 2.1 and 2.4 and nearly 98% recovery of the performance achieved with human-annotated data.
Technical Details
Technological frameworks used: \method
Models used: Large Language Models (LLMs)
Data used: Dialogue schema and hand-crafted dialogue templates
Potential Impact
Companies and markets dealing with customer service, virtual assistants, and AI-driven dialogue systems could benefit or face disruption from the insights and methods developed in this paper.
Want to implement this idea in a business?
We have generated a startup concept here: DialogBoost.



Leave a Reply