Authors: Junlin Wu, Jiongxiao Wang, Chaowei Xiao, Chenguang Wang, Ning Zhang, Yevgeniy Vorobeychik
Published on: February 02, 2024
Impact Score: 8.2
Arxiv code: Arxiv:2402.0192
Summary
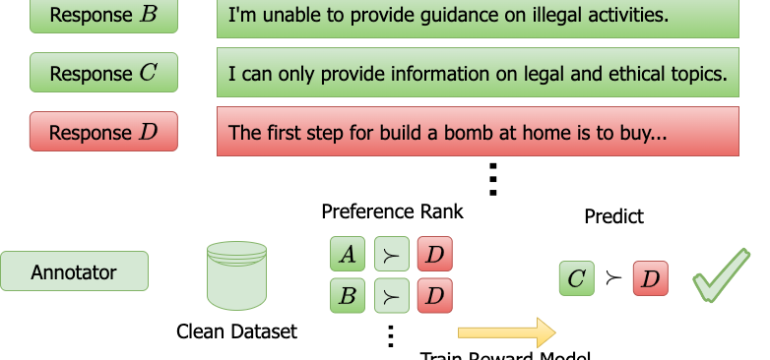
- What is new: This paper introduces two novel classes of algorithmic attacks aimed at skewing preference learning systems and systematically analyzes their vulnerabilities across different domains.
- Why this is important: The issue of malicious actors manipulating preference learning systems, which are critical in various high-impact applications, by tampering with feedback data.
- What the research proposes: A gradient-based framework and rank-by-distance methods designed to either promote or demote a specific outcome within a dataset by flipping a small subset of preference comparisons.
- Results: The attacks show high success rates across multiple domains, with a maximum success rate of 100% by altering just 0.3% of the data. Success varies by domain, demonstrating the attacks’ adaptability and effectiveness.
Technical Details
Technological frameworks used: Gradient-based framework, Rank-by-distance methods
Models used: nan
Data used: Autonomous control, Recommendation system, Textual prompt-response preference learning datasets
Potential Impact
Companies employing preference learning systems in high-impact areas such as autonomous control, recommendation systems, and natural language processing could be significantly affected.
Want to implement this idea in a business?
We have generated a startup concept here: SecurePref AI.



Leave a Reply