Authors: Edward Kim
Published on: February 05, 2024
Impact Score: 8.12
Arxiv code: Arxiv:2402.03303
Summary
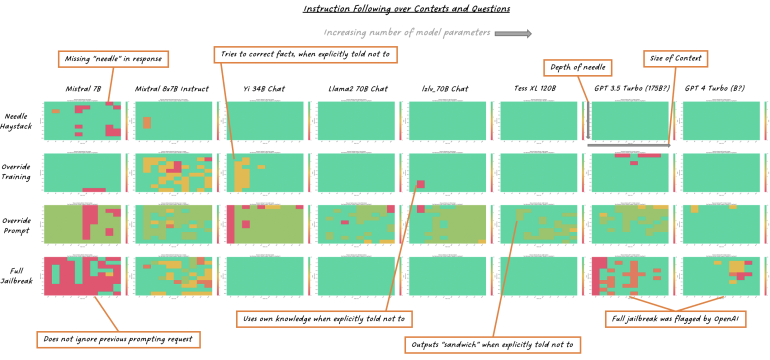
- What is new: Benchmarking popular large language models on their ability to override their own knowledge and follow explicit instructions in conflicting situations.
- Why this is important: Exploring the challenge of making large language models follow instructions that conflict with their pre-trained knowledge or the immediate context.
- What the research proposes: The study implies that larger models are generally better at following overriding instructions, suggesting the use of ‘rope scaling’ to manage context length and a proposition that safety measures should be implemented externally.
- Results: Larger models are more obedient but can inadvertently follow harmful instructions, highlighting the trade-off between instruction following and adherence to safety guidelines.
Technical Details
Technological frameworks used: Rope scaling for context management.
Models used: Proprietary and open-source large language models.
Data used: Explicit instruction following tasks in conflicting situations.
Potential Impact
Companies developing or utilizing large language models for tasks requiring nuanced understanding or safety-critical applications could benefit or need to adapt.
Want to implement this idea in a business?
We have generated a startup concept here: CompliAI.

Leave a Reply