Authors: Kevin Wu, Eric Wu, Ally Cassasola, Angela Zhang, Kevin Wei, Teresa Nguyen, Sith Riantawan, Patricia Shi Riantawan, Daniel E. Ho, James Zou
Published on: February 03, 2024
Impact Score: 8.35
Arxiv code: Arxiv:2402.02008
Summary
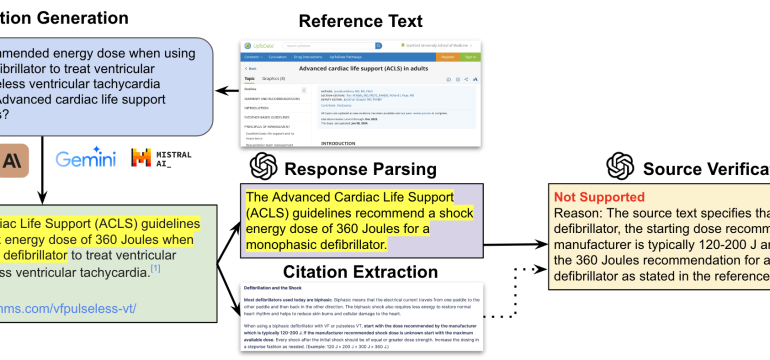
- What is new: This study investigates the reliability of sources cited by large language models (LLMs) in the context of medical information, presenting a novel approach to validate source relevance with GPT-4 and introducing an automated pipeline, SourceCheckup, for evaluation.
- Why this is important: Existing LLMs often cite sources for their responses, but the reliability and relevance of these sources in supporting the claims have not been thoroughly evaluated, especially in medical contexts where accuracy is critical.
- What the research proposes: The study leverages GPT-4’s ability to validate source relevance against expert opinions and introduces SourceCheckup, an automated tool to evaluate the reliability of sources cited by LLMs in supporting their statements.
- Results: Findings indicate significant discrepancies in the supportiveness of sources cited by LLMs, with about 50% to 90% of LLM responses not fully supported by their sources, and around 30% of individual statements by GPT-4 with RAG being unsupported.
Technical Details
Technological frameworks used: SourceCheckup, an automated evaluation pipeline.
Models used: GPT-4, including use of retrieval augmented generation (RAG) techniques.
Data used: A curated dataset of 1200 medical questions and expert annotations.
Potential Impact
This research could impact the healthcare information market, telehealth companies relying on LLMs for patient interaction, and developers of healthcare-focused AI applications by highlighting the need for accuracy and reliability in medical information provided by LLMs.
Want to implement this idea in a business?
We have generated a startup concept here: MediCheckAI.

Leave a Reply