Authors: Dimitrios P. Panagoulias, Maria Virvou, George A. Tsihrintzis
Published on: January 28, 2024
Impact Score: 8.38
Arxiv code: Arxiv:2402.0173
Summary
- What is new: A novel evaluation paradigm for assessing the accuracy of large language models (LLMs) in medical diagnosis using multimodal multiple-choice questions.
- Why this is important: The correctness and accuracy of Large Language Models in generating medical diagnoses have not been properly evaluated.
- What the research proposes: Proposed a two-step evaluation method that combines multimodal LLM evaluation via structured interactions with follow-up, domain-specific analysis.
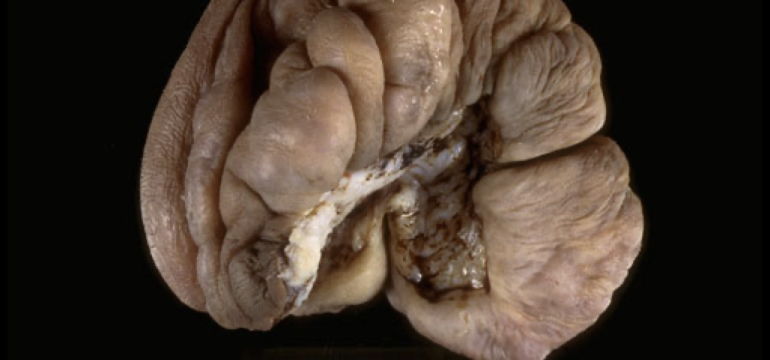
- Results: GPT-4-Vision-Preview achieved approximately 84% correctness in diagnoses across a range of diseases and conditions in Pathology.
Technical Details
Technological frameworks used: nan
Models used: GPT-4-Vision-Preview
Data used: Publicly available multimodal multiple-choice questions (MCQs) in Pathology
Potential Impact
Healthcare diagnostics, medical research organizations, AI development companies focusing on medical applications
Want to implement this idea in a business?
We have generated a startup concept here: MediCheckAI.

Leave a Reply