Authors: Ziyi Zhou, Liang Zhang, Yuanxi Yu, Mingchen Li, Liang Hong, Pan Tan
Published on: February 03, 2024
Impact Score: 8.22
Arxiv code: Arxiv:2402.02004
Summary
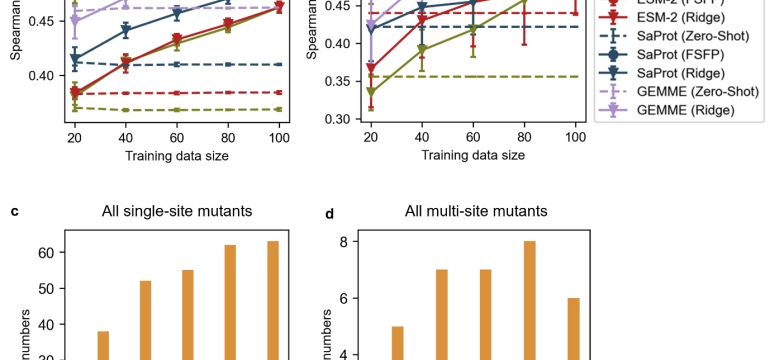
- What is new: Introduction of FSFP, a training strategy that enhances protein language models’ accuracy in predicting protein fitness under data scarcity.
- Why this is important: Existing protein language models struggle with accuracy and interpretability in predicting protein fitness, and improvements require substantial labeled data.
- What the research proposes: FSFP employs meta-transfer learning, learning to rank, and parameter-efficient fine-tuning to optimize models with few labeled examples.
- Results: FSFP outperforms both unsupervised and supervised baselines in 87 datasets, showcasing effectiveness in AI-guided protein design.
Technical Details
Technological frameworks used: Meta-transfer learning, learning to rank, parameter-efficient fine-tuning
Models used: Pre-trained protein language models
Data used: Labeled single-site mutants from target proteins
Potential Impact
Biotech companies and markets focusing on protein engineering and related R&D
Want to implement this idea in a business?
We have generated a startup concept here: ProFitBoost.


Leave a Reply