Authors: Simin Fan, Matteo Pagliardini, Martin Jaggi
Published on: October 23, 2023
Impact Score: 8.22
Arxiv code: Arxiv:2310.15393
Summary
- What is new: Introducing DoGE, a method for optimizing domain weights in the pretraining of LLMs for better generalization.
- Why this is important: Current Large Language Models struggle with generalization due to unoptimized pretraining data composition.
- What the research proposes: DoGE uses a two-stage process with a proxy model and bi-level optimization to fine-tune domain weights, enhancing model generalization.
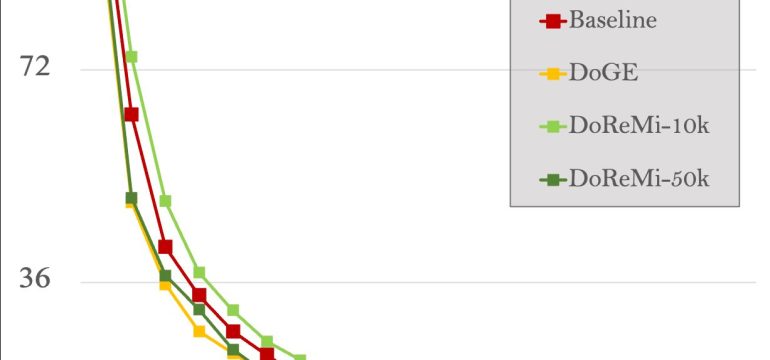
- Results: DoGE shows improved perplexity and few-shot reasoning accuracies on the SlimPajama dataset and out-of-domain tasks.
Technical Details
Technological frameworks used: DoGE
Models used: Proxy model, larger base model
Data used: SlimPajama dataset
Potential Impact
Tech companies involved in NLP, AI services, and educational technology platforms.
Want to implement this idea in a business?
We have generated a startup concept here: OptiLingo.


Leave a Reply