Authors: Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, Zheng Liu
Published on: February 05, 2024
Impact Score: 8.22
Arxiv code: Arxiv:2402.03216
Summary
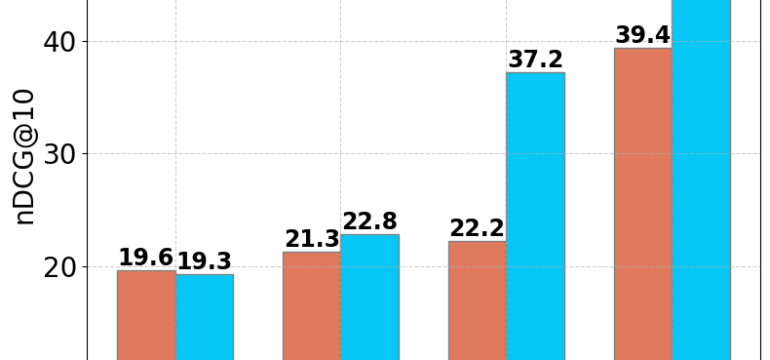
- What is new: M3-Embedding’s ability to support 100+ languages, its unified foundation for dense, multi-vector, and sparse retrieval, and its handling of varying input sizes up to 8192 tokens.
- Why this is important: Existing embedding models lack versatility in language support, retrieval functionality, and input granularity.
- What the research proposes: M3-Embedding, which provides a versatile approach to embedding with multi-linguality, multi-functionality, and multi-granularity.
- Results: New state-of-the-art performances on multi-lingual and cross-lingual retrieval tasks.
Technical Details
Technological frameworks used: nan
Models used: Self-knowledge distillation, optimized batching strategy for large batch sizes and high training throughput.
Data used: nan
Potential Impact
Companies involved in multi-lingual information retrieval, cross-lingual data analysis, and international digital markets could significantly benefit or be disrupted by M3-Embedding’s capabilities.
Want to implement this idea in a business?
We have generated a startup concept here: LinguaSphere.


Leave a Reply